A Simple and Effective Pruning Approach for
Large Language Models
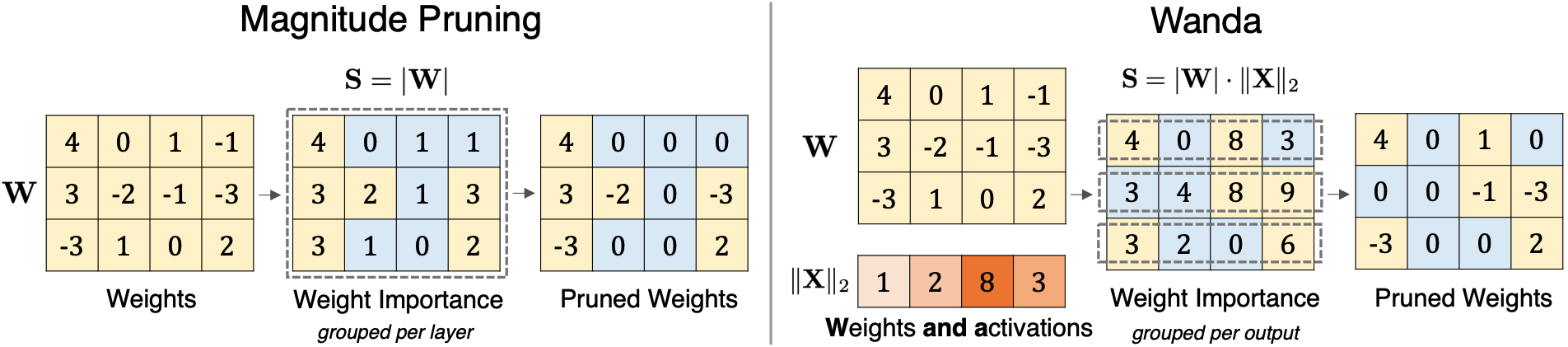
Compared to magnitude pruning which removes weights solely based on their magnitudes, our proposed method Wanda (Pruning by Weights and activations) removes weights on a per-output basis, by the product of weight magnitudes and input activation norms.
Abstract
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance.
Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive.
In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update.
Implementation
Our method Wanda can be implemented in a few lines of PyTorch code:
# W: weight matrix (C_out, C_in);
# X: input matrix (N * L, C_in);
# s: desired sparsity, between 0 and 1;
def prune(W, X, s):
metric = W.abs() * X.norm(p=2, dim=0) # get the Wanda pruning metric
_, sorted_idx = torch.sort(metric, dim=1) # sort the weights per output
pruned_idx = sorted_idx[:,:int(C_in * s)] # get the indices of the weights to be pruned
W.scatter_(dim=1, index=pruned_idx, src=0) # get the index of pruned weights
return W
For details, check out our code repo.
Results
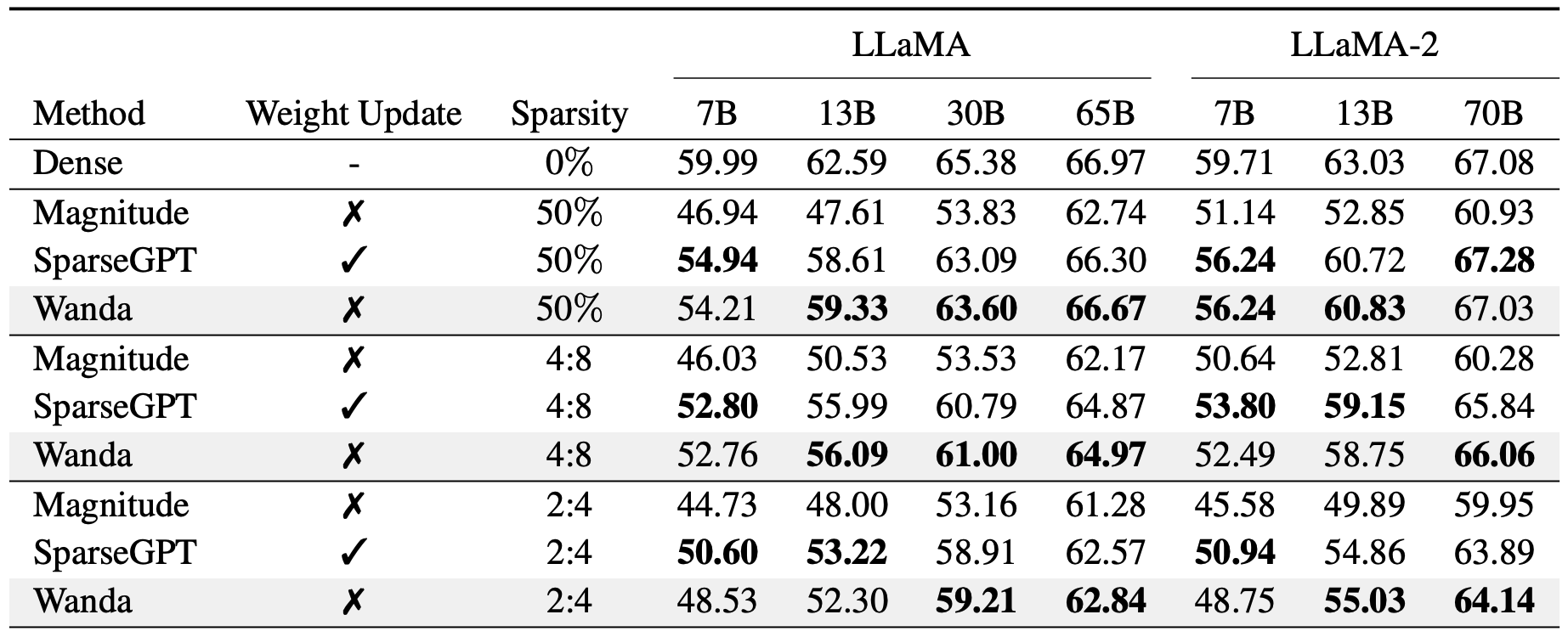
We evaluate the zero-shot performance of pruned LLMs. Here we report the mean zero-shot accuracies on 7 common sense reasoning tasks from EleutherAI LM eval harness benchmark, which are described in Section 4.1 of the paper.
Our method Wanda outperforms the well-established magnitude pruning approach by a large margin, while also competes favorably with prior best method SparseGPT involving intensive weight updates.
Wanda consistently finds effective pruned networks across various sparsity levels, without any weight updates. This suggests that LLMs have effective sparse sub-networks that are exact, instead of them merely existing in the neighborhood of the original weights.
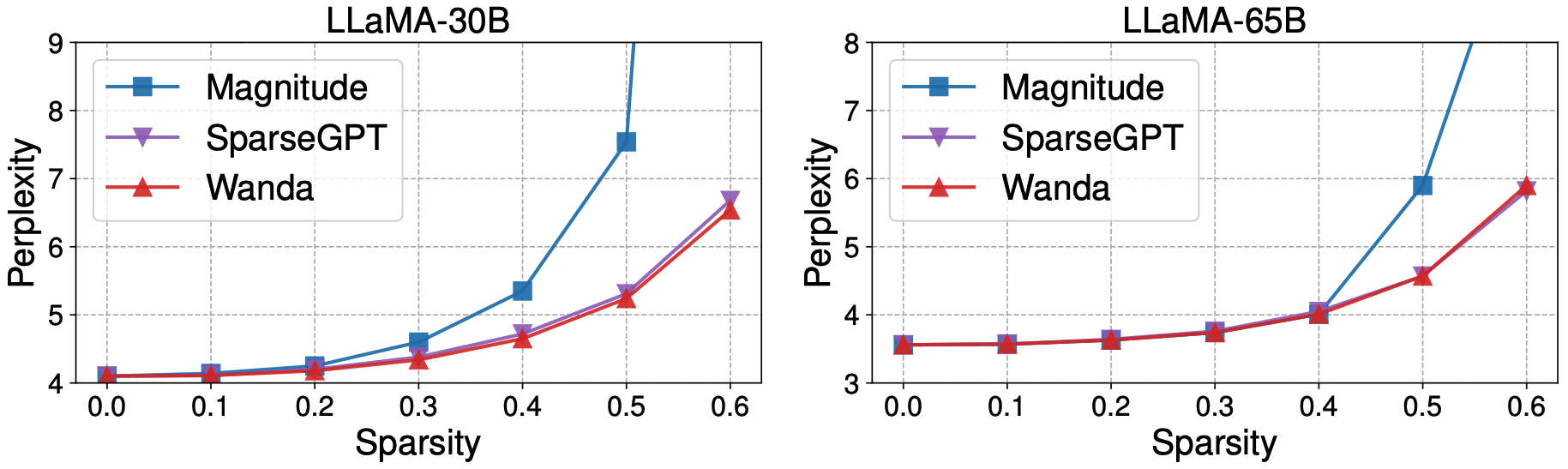
Our analysis shows that the pruning configuration of Wanda delivers the best result among existing pruning metrics and comparison groups.
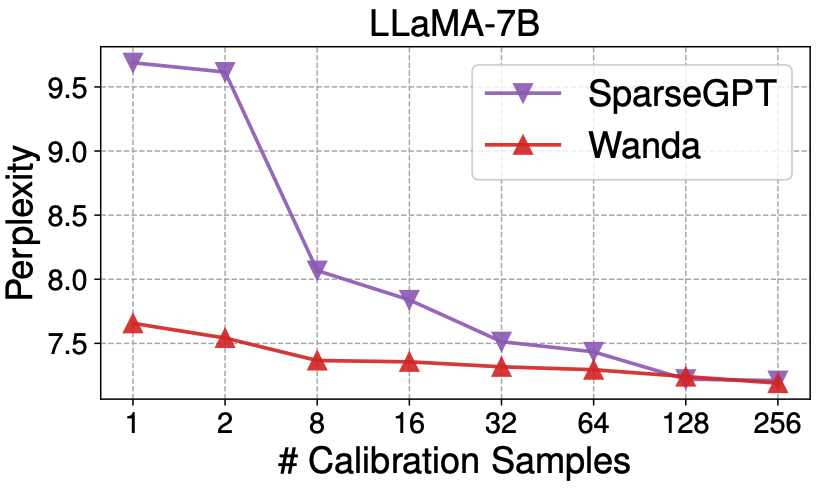
We find that our method Wanda is more robust and stable with less amount of calibration data.
For more results and analysis, please take a look at our full paper.
Paper
 |
M. Sun, Z. Liu, A. Bair, J. Z. Kolter.
A Simple and Effective Pruning Approach for Large Language Models.
ArXiv Preprint, 2023. link
|
Acknowledgements
We thank Yonghao Zhuang for valuable discussions. This project is insipired from the amazing work of SparseGPT. We thank the authors for releasing their code. Mingjie Sun and Anna Bair were supported by the Bosch Center for Artificial Intelligence. We further thank Richard Zhang for his project page template.
Correspondence
mingjies [at] cs [dot] cmu [dot] edu, zhuangl [at] meta [dot] com
|