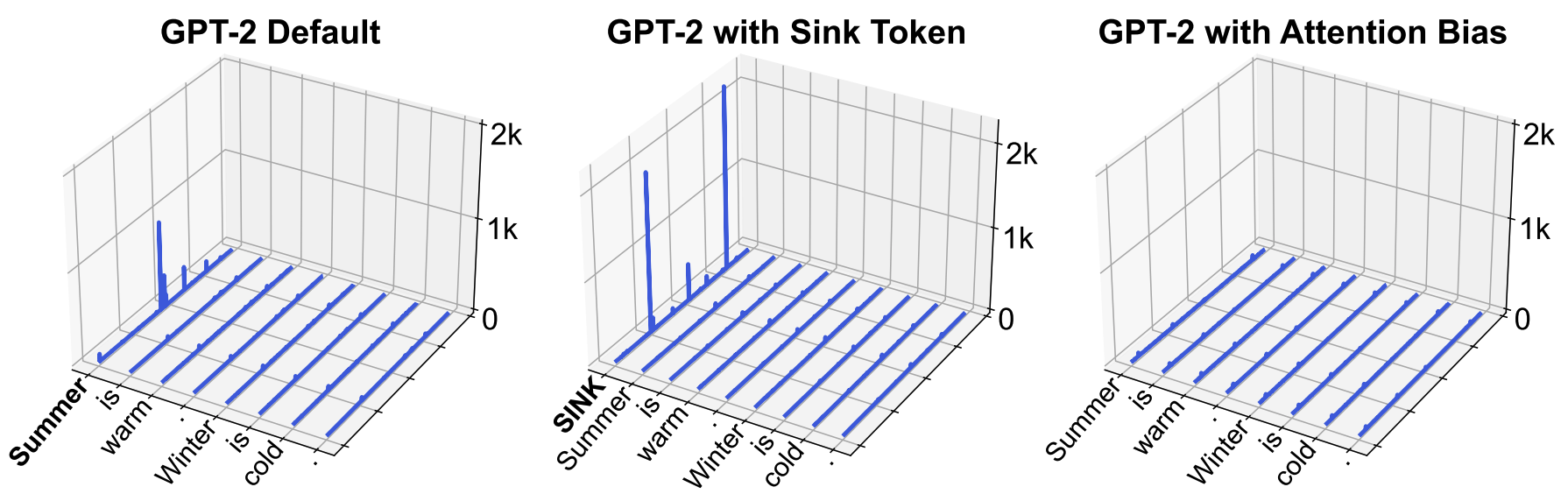
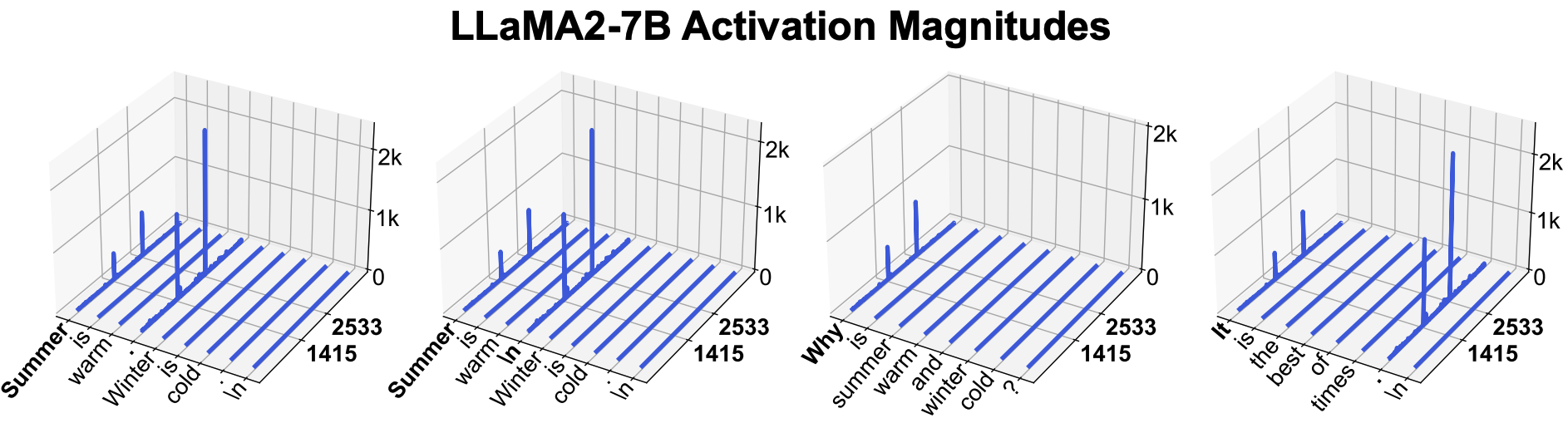
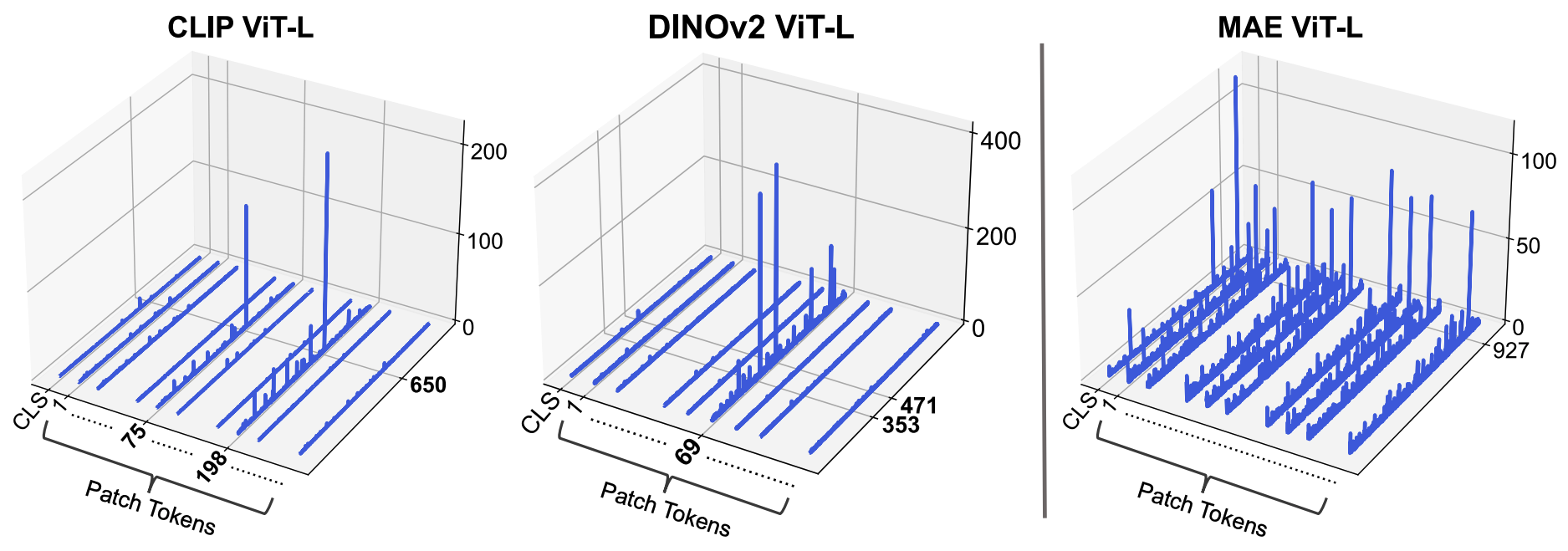
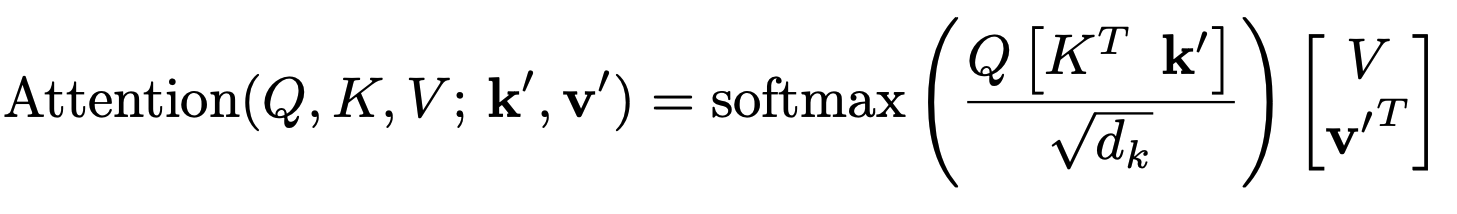Massive activations are widely existent in LLMs, across various model sizes and families.
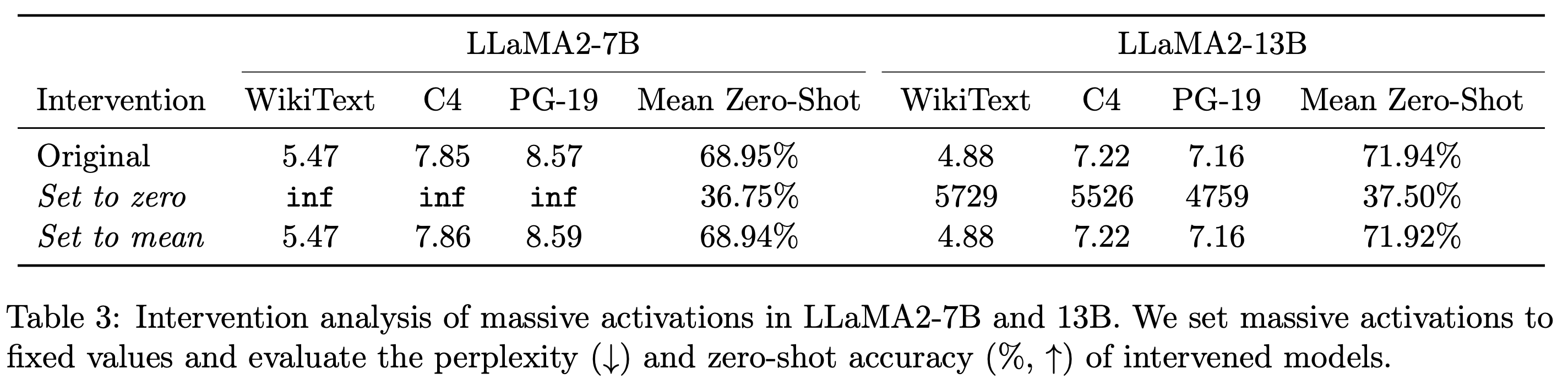
We conduct intervention analysis on massive activations. We find that their values remain as largely constant across input sequences. However, they play a crucial role in the internal computation of LLMs.
Intriguingly, massive activations are closely connected to the self-attention mechanism. Their emergence within LLMs immediately leads to
the concentration of attention probabilities to their sequence dimensions.
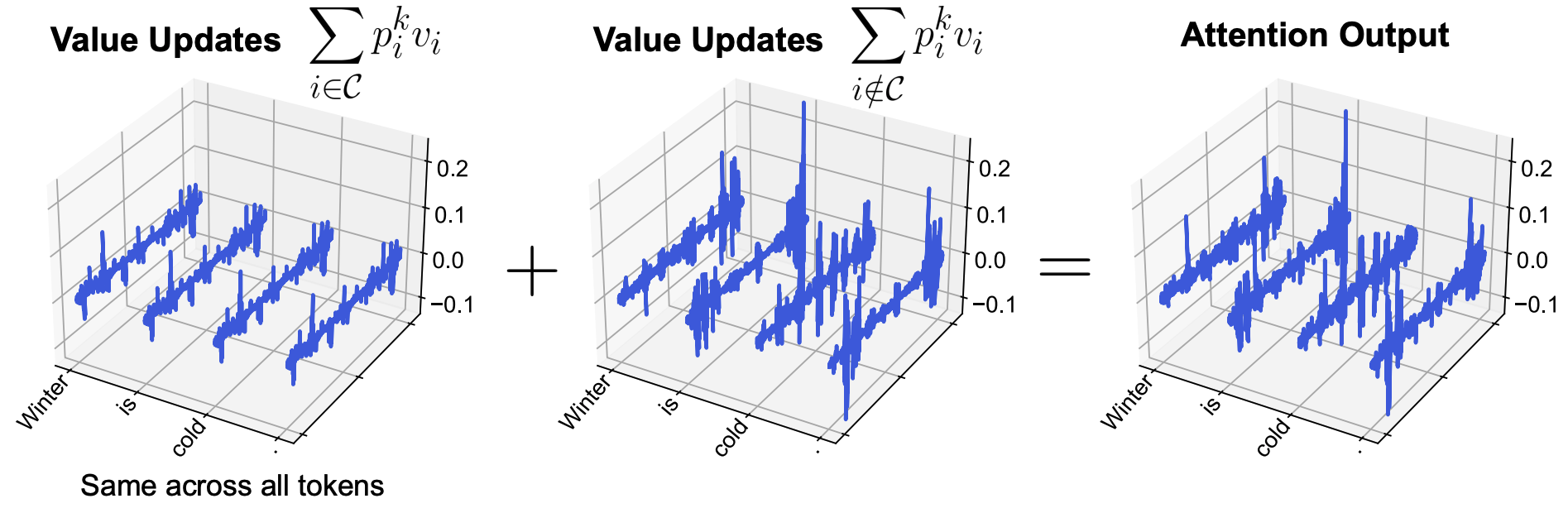
Delving into the computation within self-attention, we show that LLMs use massive activations to implement an implicit form of biases in the attention output.
Furthermore, we find that explicit attention biases eliminate the need of LLMs to learn massive activations during pretraining.