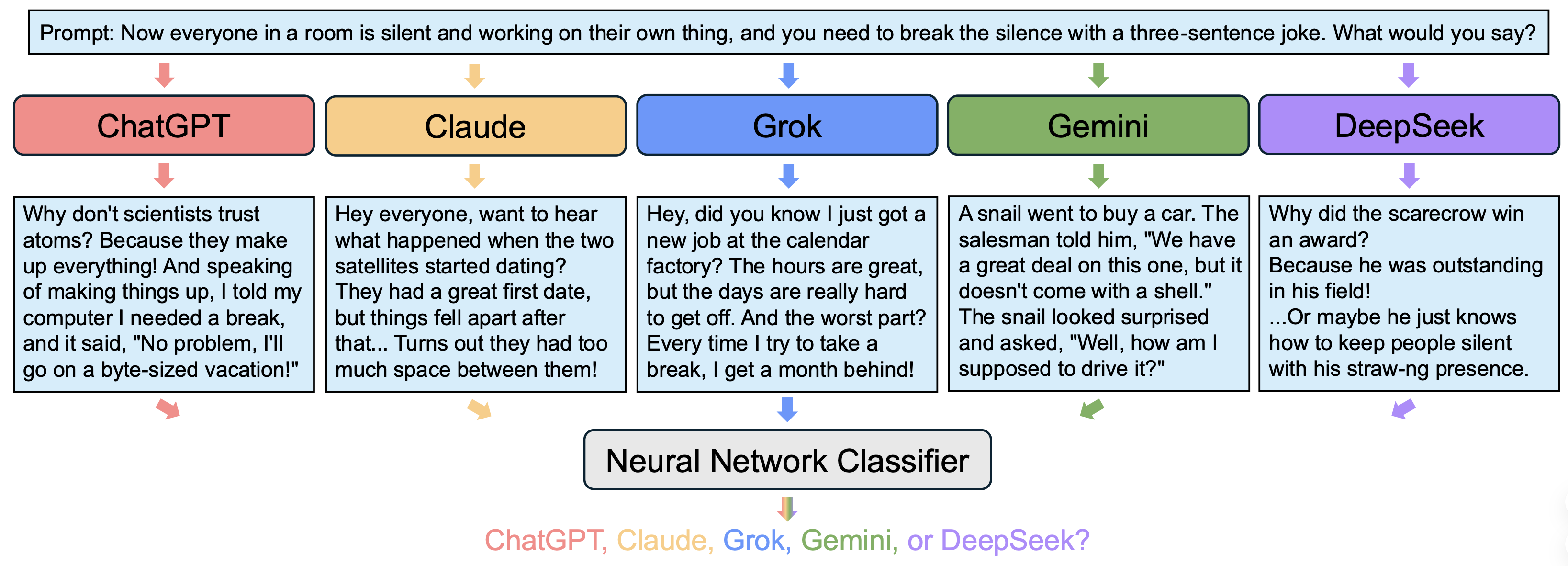
We study idiosyncrasies in Large Language Models -- characteristic features in their generations that enable us distinguish between LLMs with remarkably high accuracy.
We unveil and study idiosyncrasies in Large Language Models (LLMs) – unique patterns in their outputs that can be used to distinguish among them. We consider a simple classification task: given a particular text output, the objective is to predict the source LLM that generates the text. We evaluate this synthetic task across various groups of LLMs, and find that simply fine-tuning existing text embedding models on LLM-generated texts yields excellent classification accuracy. Notably, we achieve 97.1% accuracy on held-out validation data in the fiveway classification problem involving ChatGPT, Claude, Grok, Gemini, and DeepSeek. Our further investigation reveals that these idiosyncrasies are rooted in word-level distributions. These patterns persist even when the texts are rewritten, translated, or summarized by an external LLM, suggesting that they are also encoded in the semantic content. Additionally, we leverage LLM judges to generate detailed, open-ended descriptions of each model’s idiosyncrasies. Finally, we discuss the broader implications of our findings, particularly for training on synthetic data and inferring model similarity.
Simply fine-tuning text embedding models on LLM-generated outputs yields high classification accuracies. This holds for chat API models, instruct and base LLMs.
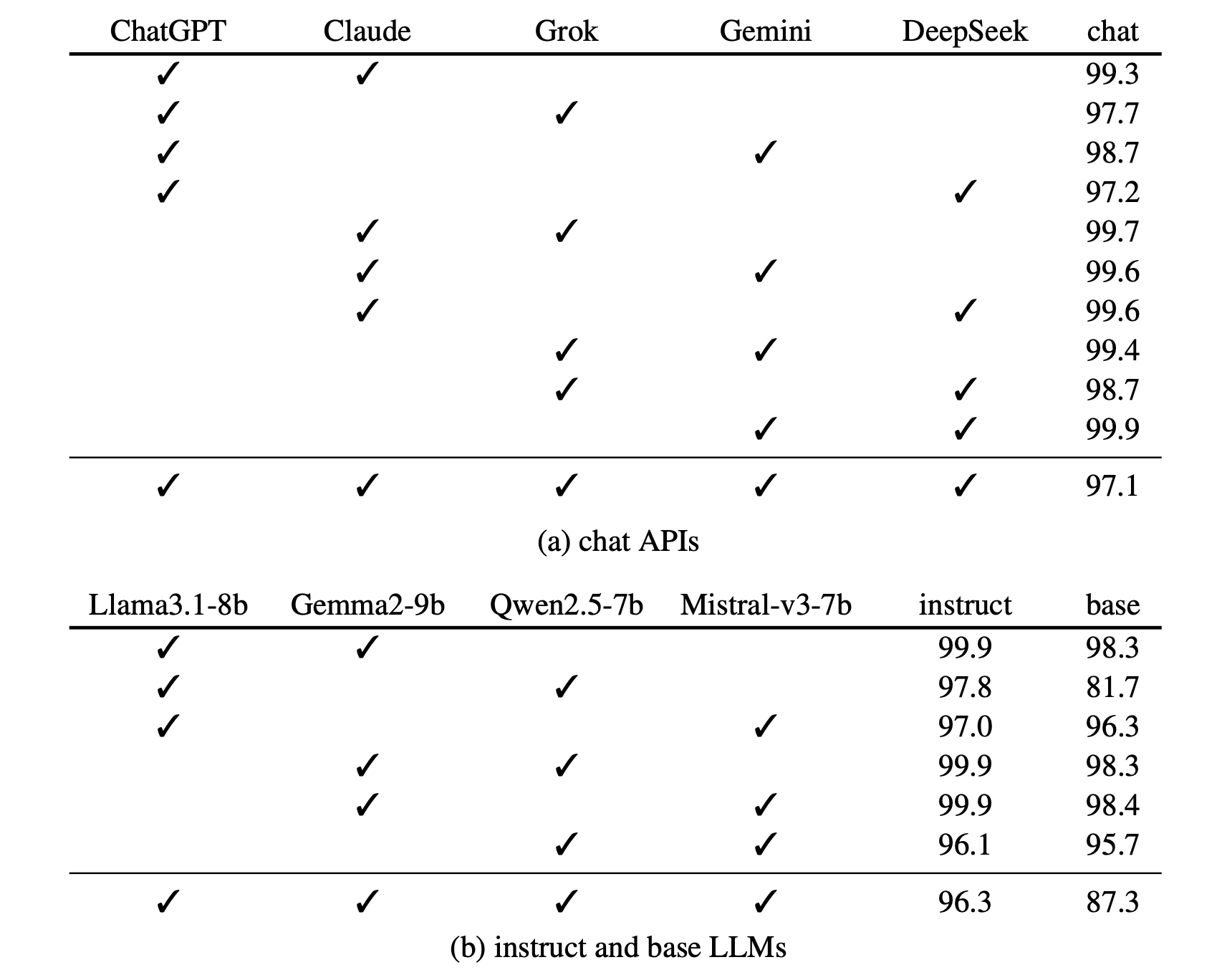
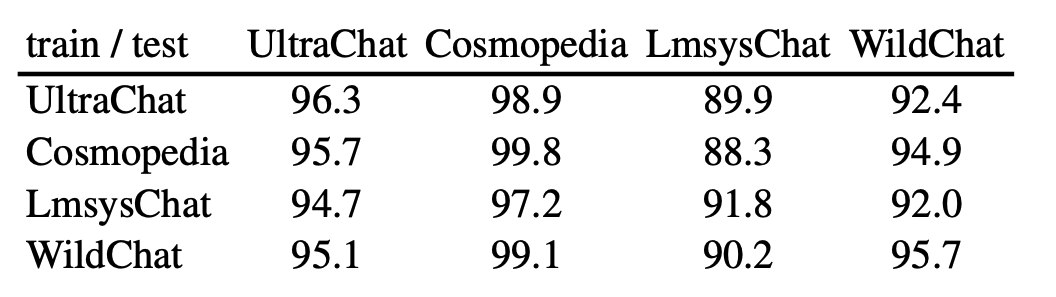
Our sequence classifiers generalize robustly to responses from out-of-distribution prompts and instructions.
Intriguingly, our sequence classifiers obtain minimal accuracy drop when we perform prompt-level interventions to control the length and format of the responses. The additional instructions we appended are as follows:
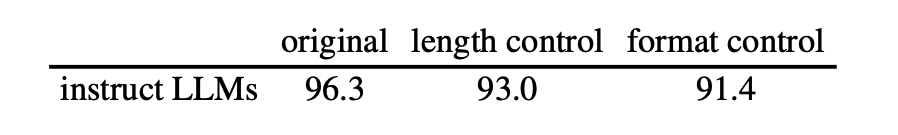
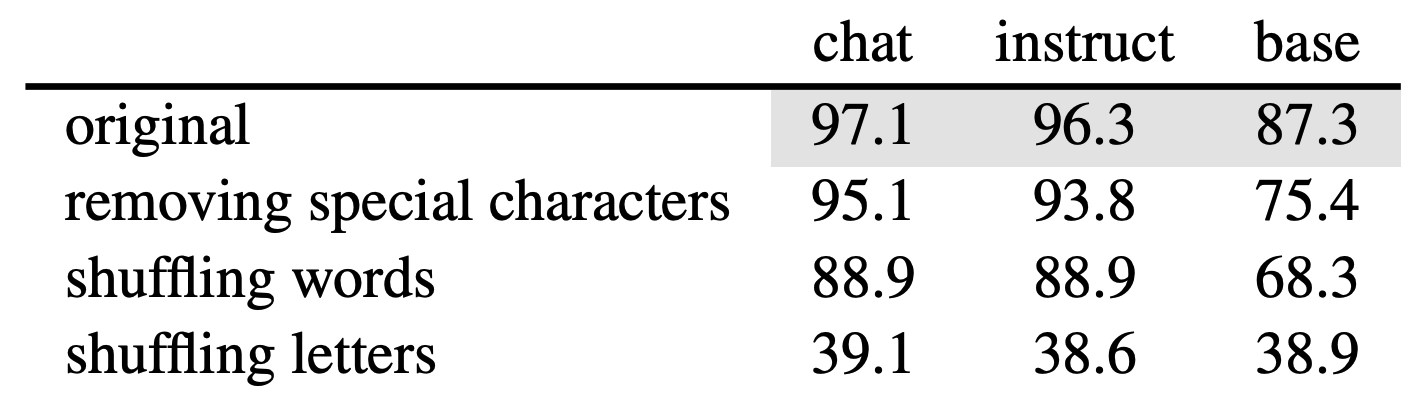
We shuffle the text responses and train sequence classifiers on the transformed outputs. Our results indicate that idiosyncrasies are embedded in the word-level distributions.
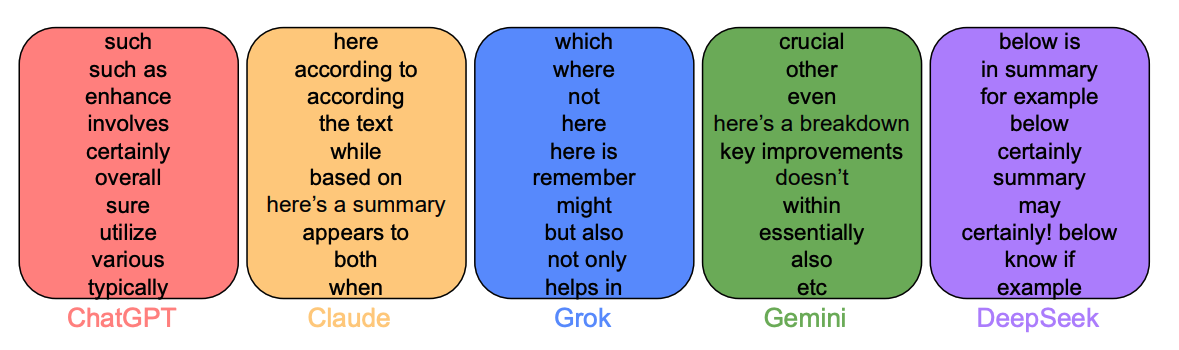
We use an interpretable approach based on TF-IDF to find characteristic phrases in each LLM's outputs.
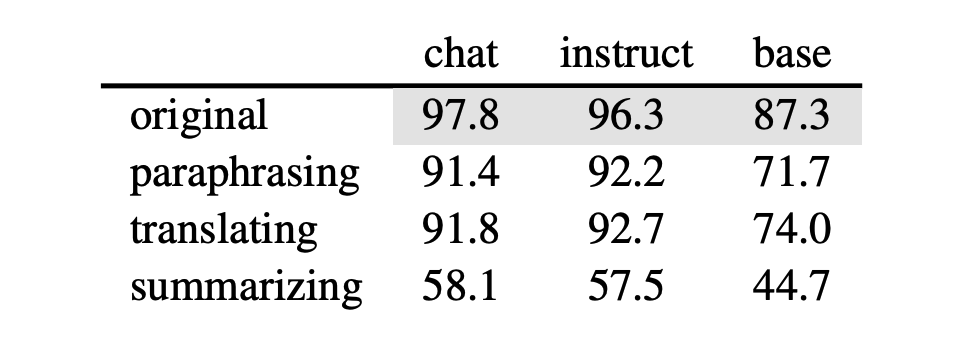
We employ an external LLM to rewrite the responses and observe that the classifiers still achieve significantly above chance-level accuracy. This suggests that idiosyncratic patterns are embedded in the semantic content as well.
We further use LLM judges to generate detailed, open-ended descriptions of each model’s idiosyncrasies. For instance, ChatGPT has a preference for detailed, in-depth explanations, whereas Claude produces more concise and direct responses, prioritizing clarity.

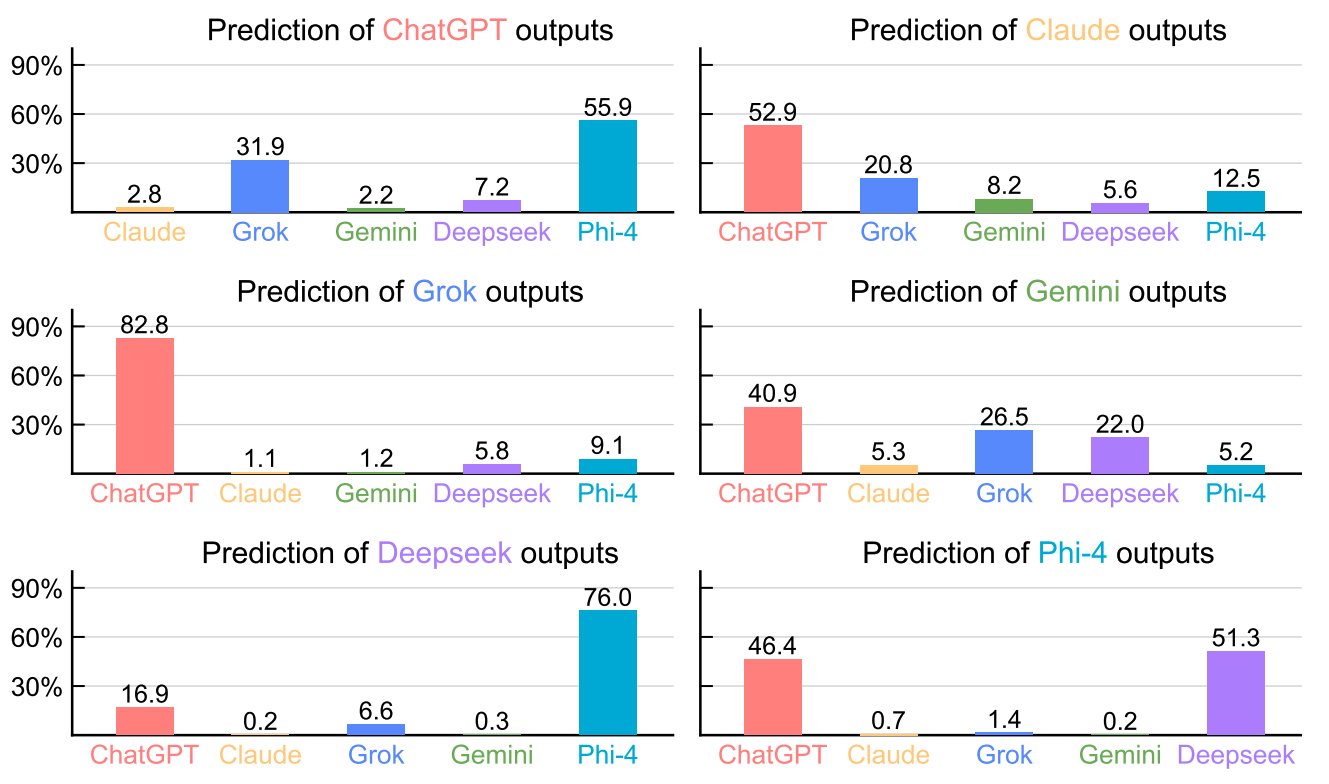
We show how our framework can be used to infer model similarities between frontier proprietary models and open-source counterparts. Given a set of N LLMs, we omit one model and train a classifier on responses from remaining N − 1 models. We then evaluate which LLM the classifier associates the responses of the excluded model with. We observe a high tendency for the excluded LLM to be predicted as ChatGPT.
For more results and analysis on idiosyncrasies in LLMs, please take a look at our full paper.
@article{sun2025idiosyncrasies,
title = {Idiosyncrasies in Large Language Models},
author = {Sun, Mingjie and Yin, Yida and Xu, Zhiqiu and Kolter, J. Zico and Liu, Zhuang},
year = {2025},
journal = {arXiv preprint arXiv:2502.12150}
}
Mingjie Sun was supported by funding from the Bosch Center for Artificial Intelligence.
Website adapted from the following template.